Partindo do princípio de que o software livre é mesmo desenvolvido mais rápido, imagine que, de repente, por algum motivo qualquer, a velocidade de desenvolvimento do software não livre dobre. O que acontece agora? Ele passa o software livre? Se não, imagine que esta velocidade é agora triplicada, ou miltiplicada por 100, ou por 1000... Dizer que o software livre cresce assintoticamente mais rápido do que o não livre é o mesmo que dizer que mesmo que a velocidade do software não livre seja multiplicada por qualquer valor (10, 100, 1000...) ele não consegue passar o software livre no longo prazo. Mas isso só vale para o longo prazo. No curto prazo, o software livre pode ser mais lento mesmo sendo assintoticamente mais rápido.
Porque eu desconfio disso? Bom, o software livre parece mesmo mais rápido. É algo impressionante de se ver um pacote de software livre de repente começar a crescer e, em poucos meses, percorrer o mesmo caminho em que programas não livres gastaram décadas. Mas por que assintoticamente mais rápidos? Eu não fui o único que notou isso (mas perdi is links que tinha, quando encontrar, coloco aqui): Os programas livres começam pequenos, bem pequenos, e crescendo devagar. Enquanto isso, as alternativas proprietárias (quando existem) começam maiores e crescendo rápido. De repente, porém, sem nenhum aviso, os programas livres passam os proprietários. Isso é sinal de que são assintoticamente mais rápidos.
Outra pergunta muito boa é: Como isso é possível? Os dois são programas, feitos por programadores que não são muito diferentes nos dois mundos (muitas vezes são até a mesma pessoa). Como um pode ser tão mais rápido do que o outro? Não pode ser porque mais programadores trabalham em um deles, senão a diferença seria somente proporcional, nunca assintótica.
Encontrei uma resposta para essa pergunta enquanto lia "The Art of Unix Programming". Reaproveitamento de código! Isso, aliado à tendência de descartar código mal feito nos programas livres pode aumentar a produtividade dos programadores.
O reaproveitamento de código é uma daquelas coisas que todo mundo diz que é bom, mas ninguém faz. Pelo menos no mundo do software proprietário. Já no mundo do software livre, uma pessoa costuma se deparar com centeneas de bibliotecas compartilhadas entre os programas que usa. Isso era um dos maiores problemas nos sistemas mais antigos, em que o tratamento de dependências era manual. Ou seja, no software livre, o código é de fato reaproveitado.
Mas que ganho isso gera? Bom, para isso, vamos comparar os diferentes programas pela sua funcionalidade. Entendo por "funcionalidade" a quantidade de funções diferentes que o programa pode executar. É uma medida subjetiva, e não coincide com a utilidade, mas deixemos estes problemas para depois. Para fins de modelo, proponho que todas as funções "custam" o mesmo tempo de programação. Sem reaproveitamento de código, então, a funcionalidade x custo é uma reta:
 Os números não são importantes, só estão ai para comparar com os outros gráficos. Preferí contar somente o custo de "melhorias" no software, logo, a funcionalidade não começa do zero (só pra constar, sai do 30). É interessante notar que não há nenhum ponto especial (fora o de custo zero) no gráfico acima. Ou seja, alguém que observe o desenvolvimento do programa não vai notar nada de diferente, só um crescimento constante.
Os números não são importantes, só estão ai para comparar com os outros gráficos. Preferí contar somente o custo de "melhorias" no software, logo, a funcionalidade não começa do zero (só pra constar, sai do 30). É interessante notar que não há nenhum ponto especial (fora o de custo zero) no gráfico acima. Ou seja, alguém que observe o desenvolvimento do programa não vai notar nada de diferente, só um crescimento constante.Com o reaproveitamento de código, a coisa muda. Idealmente, quanto mais código o programador tem à sua disposição, menos ele tem que escrever para criar uma certa funcionalidade. Imagino que seja rasoável esperar que para criar uma certa função, a cada N funções que ele possua em bibliotecas ou que possa recortar e colar em seu programa, ele precise escrever N/y linhas a menos, onde y é constante (y > 1, é claro). Assim, o custo de cada função diminui proporcionalmente à funcionalidade que ele já possui implementada. Isso nos dá que a funcionalidade x custo é uma exponencial:

De novo, os números não são importantes. De novo, a funcionalidade não sai do zero (apesar do que parece), mas de um valor mais baixo do que no caso anterior. Isso foi proposital, já que o software livre normalmente é "lançado" com menos funcionalidade do que o proprietário, e não influencia no modelo, só vai gerar uma figura mais legal no final. (Só pra constar, a base é 1.013.) A exponencial também não tem nenhum ponto especial (fora o de custo zero), assim, alguém acompanhando o desenvolvimento deste programa não vai perceber nada de diferente em nenhum momento. O programa simplesmente continua crescendo, só um pouco mais rápido do que crescia a até pouco tempo atrás.
Comparando os dois gráficos, porém, aparecem dois pontos especiais:
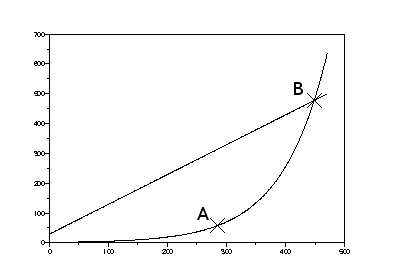 No ponto A, a exponencial tem a mesma inclinação da reta, ou seja, o custo de se adicionar mais uma funcionalidade com ou sem reaproveitamento de código é igual. Este é o ponto em que o reaproveitamento começa a compensar, e é razoável imaginar que seja neste momento que o programa começa a chamar a atenção dos programadores, como aconteceu com o software livre lá por 97 e 98.
No ponto A, a exponencial tem a mesma inclinação da reta, ou seja, o custo de se adicionar mais uma funcionalidade com ou sem reaproveitamento de código é igual. Este é o ponto em que o reaproveitamento começa a compensar, e é razoável imaginar que seja neste momento que o programa começa a chamar a atenção dos programadores, como aconteceu com o software livre lá por 97 e 98.Já no ponto B, a funcionalidade dos dois é igual. À partir deste ponto, o reaproveitamento de código começa a gerar melhores programas. É de se esperar que neste ponto o projeto começe a chamar a atenção dos usuários, como aconteceu com o software livre em 2003 - 2004.
Bom, mas isso já está ficando muito longo, então vamos logo para o mundo real. Na verdade, essa "funcionalidade" não serve para nada. Para que todo esse bla bla bla sirva para alguma coisa, a utilidade dos programas tem que crescer com a funcionalidade. Essa proposição é bastante rasoável, bastando que os programas sejam bem gerenciados. O maior problema, porém, é que é bastante dificil confirmar este modelo. A funcionalidade não pode ser medida, a utilidade também não. Poderiamos medir o preço, mas o software livre tende a ter baixo custo, não refletindo a utilidade.
Resumindo, eu não faço a menor idéia de como confirmar o modelo. Mas se há uma diferença assintótica no comportamento dos dois, isso deve se refletir em algo que possa ser medido. Só não sei o que :(
Outro problema é que assumi que o ganho de produtividade é proporcional à funcionalidade disponível para reuso. Isso também não é comprovado, apezar de parecer razoável.